
Introduction
Recent developments in the Generative Adversarial Network ("GAN") literature has enabled particularly exciting improvements in image generation. In this blog we will explore how the techniques described in Encoder4Editng, a 2021 paper, can be used to generate realistic depictions of historical figures.
Many online examples require human post processing to achieve realistic images, we will demonstrate how with Encoder4Editing a similar quality can be achieved with only the AI model.
The commercial utility of this technology has been explored predominately in connection to the novel generation of characters for video games and deep fakes for movies. With this post we explore another opportunity, education. History teachers can make their lessons and textbooks more engaging for students by displaying these life-like renders. Enabling students to connect on a deeper level with the content by facilitating parallels to their own lives and people they know.
Interested readers can view a brief primer on how GANs work and the methods proposed in Encoder4Editing at the end of this post. Source images are provided by the MET's Open Access Collection.
Bringing History to Life
Antoninus Pius
We begin with Antoninus Pius. Pius served as Roman Emperor from AD 138 to 161. Characterized as an effective and mild mannered leader, history books have remembered Pius as the 4th of the "5 good Roman Emperors". A testament to this character is the Puellae Faustinianae, a charitable institution he founded after the passing of his wife in ~AD 140/141 for daughters from poor families.
The reference work is a marble bust from the 2nd century AD.


Roman Man Mid 1st Century A.D.
Next is the bust of a man from mid 1st century A.D. The MET suggests it is likely either a copy of a portrait from the Republic period or a new work based on the art style of the time.


Caligula
We return to Roman Emperors with Gaius Caesar (Caligula). Gaius was Roman Emperor from 37 - 41 AD, his rule ending with his assassination at age 28. History has remembered Caligula as a cruel and tyrannical leader capable of unhinged acts of violence. So potent was the hate for Caligula that modern historians indicate the degree of bias in ancient records makes distinguishing his true atrocities difficult.
Examples include allegations that at a gladiatorial games he ordered guards to throw an entire section of the civilian crowd to the lions for his amusement.
Several Game of Thrones fans drew comparisons between Joffrey Baratheon and Caligula; however, this is unsubstantiated by George R. R. Martin.
The reference work is a bust from ~ A.D. 37– 41.


British Woman 1770
The reference work for this generation is a 1770 oil on canvas painting by Joseph Wright of Derby. The subject of the work is an unknown British woman. Most of Wright's clients at the time were merchants or industrialists from the Midlands or members of the local gentry.


Roman Man Late 1st Century B.C.
The proportions of this marble bust originally led people to believe it was a depiction of Julius Caesar. Current thinking suggests the actual subject was instead someone sympathetic with Caesar's regime and sought to accentuate similarities between himself and the Emperor with this bust.
The generation highlights the strength of the techniques proposed by Encoder4Editing, with the model capable of reconstructing the broken bust.


What is a GAN?
A GAN is a modelling architecture that leverages two models, namely a Generator and a Discriminator, to make the unsupervised problem of generation easier by leveraging supervised elements.
If we first describe the generation problem then the GAN architecture can become quite intuitive. In generative modelling our goal is build a model that learns the characteristics of a training dataset so that it can then be used to create novel examples that could feasibly belong to that dataset. This problem is unsupervised as our model must work on its own to discover the patterns without help from humans in the form of labels.
We want to make this easier for the model and to explain how we can, lets imagine a fledgling artist. This fledgling artist enrolls as an apprentice of a master portrait painter. The master gives the apprentice a reference portrait and says for training the apprentice must work to recreate it until he can not tell which is the original. The apprentice submits a first draft, the master reviews and says no the eyes are wrong. The apprentice tries again and the master says the ears are wrong. The cycle repeats until one day the master says they can't discriminate between the work of the original and the apprentice. Training is complete.
In the nomenclature of GANs our apprentice is the Generator Model and the master is the Discriminator model. Our unlabeled training dataset is the reference portraits and during training we set up a supervised task where the Discriminator works to evaluate whether the generated image is real (from the original dataset) or fake. The Generator learns from this to improve it's results until it can 'fool' the Discriminator a desired percentage of the time.
Effectively the Generator and Discriminator are competing in a zero sum game and we use this to train the models so we can achieve our ultimate objective of solving the unsupervised generation problem.
Overview: Encoder4Editing
Encoder4Editing is a powerful architecture for image inversion and manipulation of the latent space to offer flexibility in image generation.
To understand why Encoder4Editing achieves such high quality for this task we must explain what a GAN latent space is. The latent space simply describes the underlying distribution from which the generator maps input to output images. This space has the property that the proximity of points is proportional to the visual proximity of output. This proximity property enables you to 'walk the latent space' that is given two points in the latent space one can create a smooth visual transition between them via traversal. By walking the latent space, properties of the generation such as age, pose angle, smile etc can also be manipulated. Below I've shown a generation for Caligula if they made it to their 60s.

The current State of the Art in GANs for human portrait generations is the StyleGan suite. Encoder4Editing uses a progressive training scheme to encourage their encoder to produce a latent code for the inverted image more closely linked to the style code in the StyleGan latent space.
This inversion step is the critical element of our task as we are less interested in latent space manipulation. Being closer to the StyleGan latent space is desirable for us as we can use their pre-trained generator on the Flicker-Faces-HQ ("FFHQ") dataset which includes 70,000 PNGs at 1024x1024 resolution of human faces.
The goal of inversion typically is to most accurately recreate the input image in the latent space so that the generated output is identical. However, we don't want to generate identical latent representations of our historical art, we want to map to human equivalents. Hence by finding the closest point in the human realistic StyleGan latent space we fail inversions typical goal and instead achieve our ultimate goal of human representation.
Attempting to use architectures not as closely linked to the StyleGan space results in unrealistic generations as they are more tied to the original source art. Hence why people have normally needed to do post editing to achieve similar results.
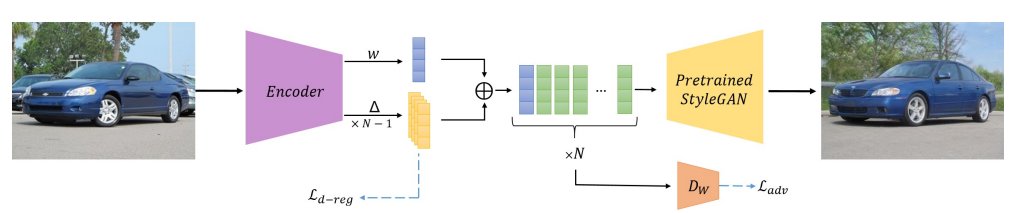
Above is a summary of the architecture. Briefly, an input image (LHS) is fed to the encoder which generates a single base style code w and n-1 offset vectors which are combined to form a vector of N latent space style codes. These are fed into the pre-trained StyleGan on our FFHQ images to complete the inversion by mapping the latent space to the generated output image (RHS). Dw refers to a Discriminator model whose purpose is to encourage the vector of StyleCodes to lie within the StyleGan latent space.
Summary
In this post we demonstrated how using GANs we can generate realistic depictions of historical figures from a reference artwork. This technique could be used to make the History curriculum more engaging for students.
A brief summary of the architecture of GANs and an overview of the contribution and relevance of Enconder4Editing for our use case was provided.
Continue the discussion
Feel free to send me an email!
📧 will@willbosler.com


